Strings are the most common data type we encounter in analytics. When we built LiquidCache – a distributed pushdown cache for DataFusion – we discovered that the way strings are stored and processed has an outsized impact on performance and memory. This post distills key points from my “On the Nature of Strings” talk at DC Systems (slides here; recording coming soon) and explains how we rethink string storage to make LiquidCache fast and lean.
TL;DR
We analyzed the PublicBI dataset (46 tables, 710 queries, 386 GB of data) and found that strings are the most important data type in the dataset: 61 % of bytes are strings, and around 40 % of projected columns are string columns.
There are four types of strings, categorized by distinct ratio and average length:
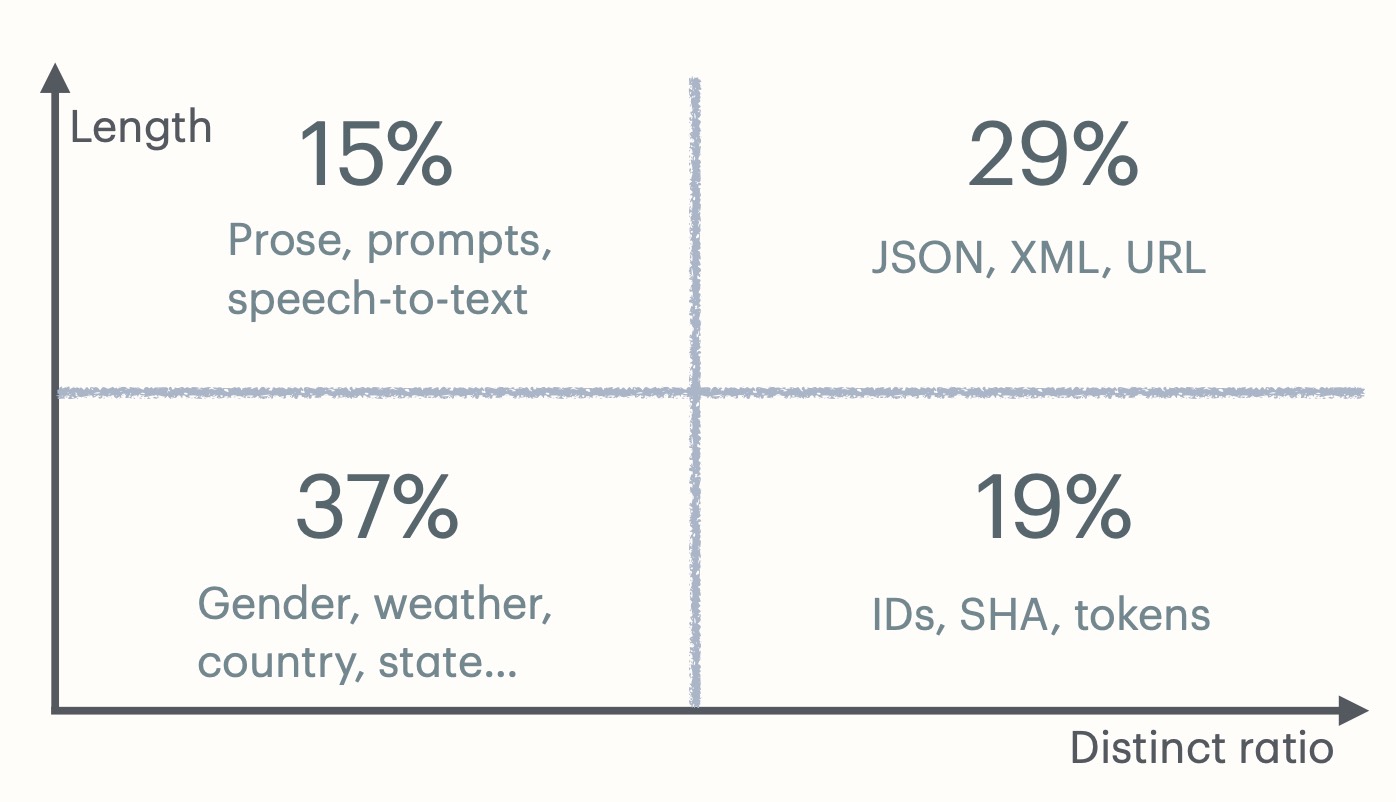
Dictionary encoding is crucial for storing string data:

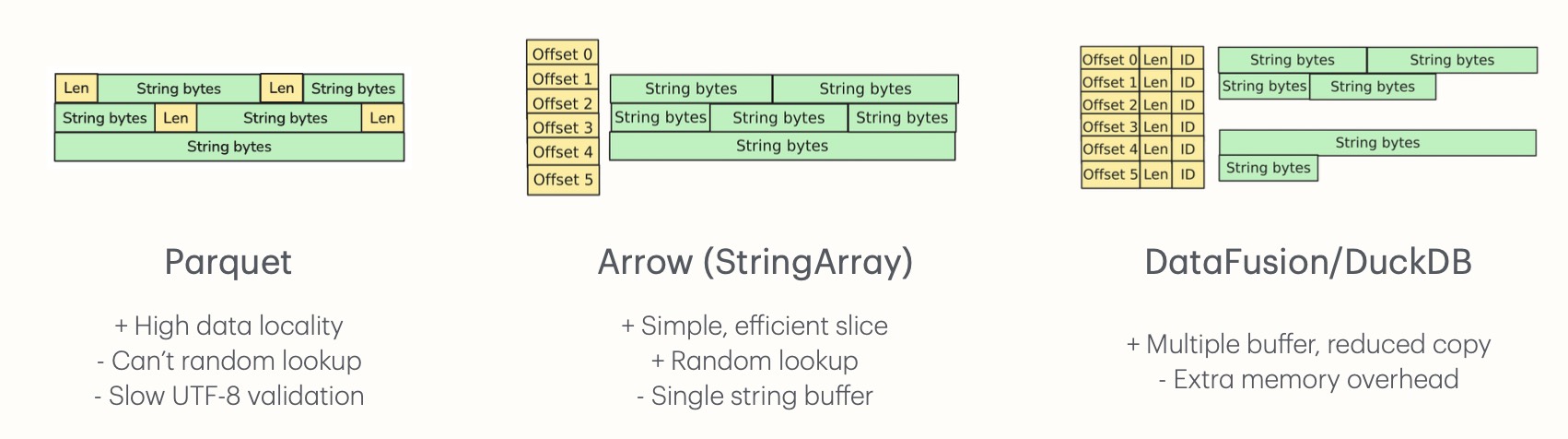
Different trade-offs for representing variable-length strings:
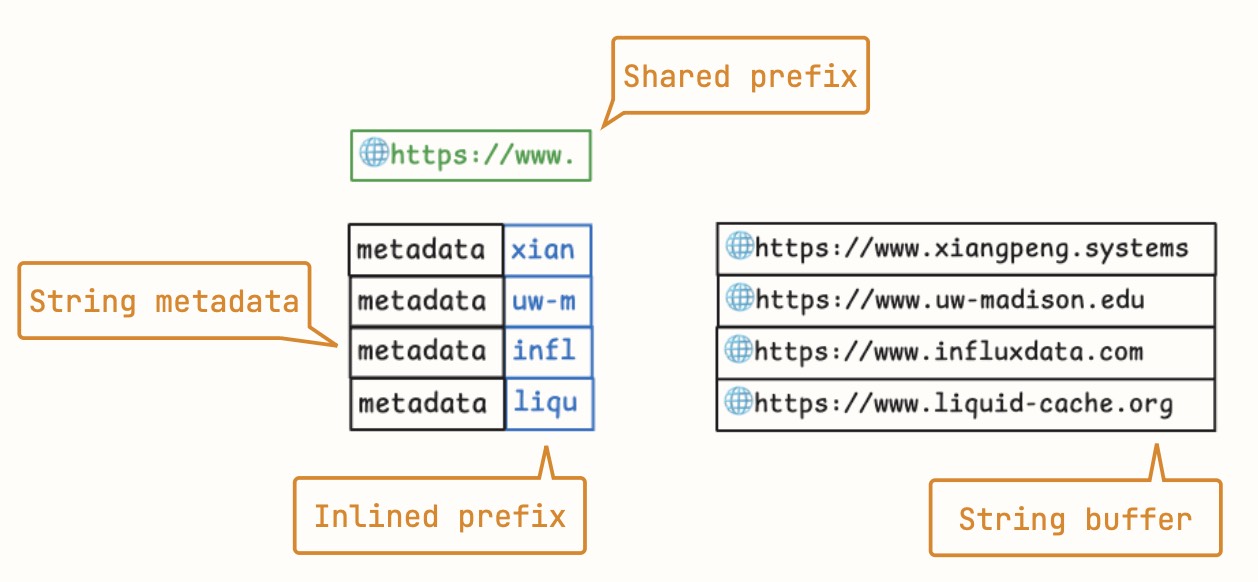
Inlined prefixes are critical for efficient comparisons:
Null handling is essential:

Compression is important:

Conclusion
- Strings are the most important data type in analytics, and we need to take them seriously.
- Strings have many subtypes and should be treated differently.
- If you’re not sure, try LiquidCache – it has a state-of-the-art string-handling pipeline and delivers best-in-class string performance with easy integration.