
LiquidCache is a caching layer that unifies the design goals of compute and storage1.
1 Check out our research paper (VLDB 2025) for more technical details.
It accelerates query performance without needing to leave Parquet.
It addresses this fundamental tension:
Storage systems want to optimize for ecosystem compatibility, and long-term, stable, open governance; industry thus gravitated towards Parquet as the de facto columnar format.
Query engines want the data to be optimized for flexible layouts, rapid evolution, and performance-first optimizations.
Instead of squeezing the last bits of performance from Parquet2, or trying to create future-proof file formats3, LiquidCache addresses this problem through a new abstraction: the caching layer.
2 Great paper on Parquet selection pushdown: Selection Pushdown in Column Stores using Bit Manipulation Instructions.
- At a glance, LiquidCache is a distributed caching service: it supports all object storage backends (S3, GCS, Azure Blob Storage, etc.), and serves all kinds of applications (knowledge bases, dashboards, etc.) deployed on all kinds of compute (Kubernetes, Lambda, etc.).
- Under the hood, LiquidCache caches Parquet as liquid data, which is ultra-optimized for compute pushdown, compressed execution, modern storage, and network‑efficient data transfer.
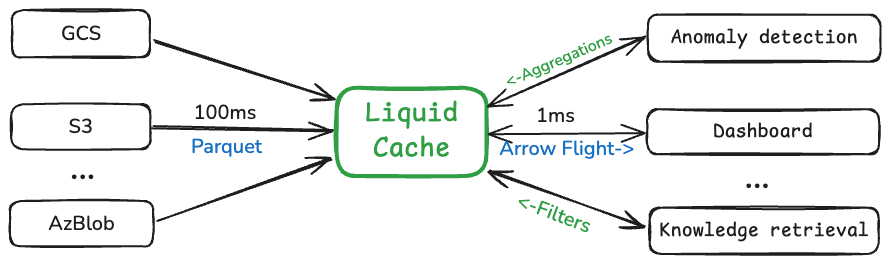
It is built on open standards: Parquet for data storage, DataFusion as the query engine, and Arrow Flight for data transfer. This makes LiquidCache highly composable – you can easily integrate it into your existing analytics stack.
Why LiquidCache?
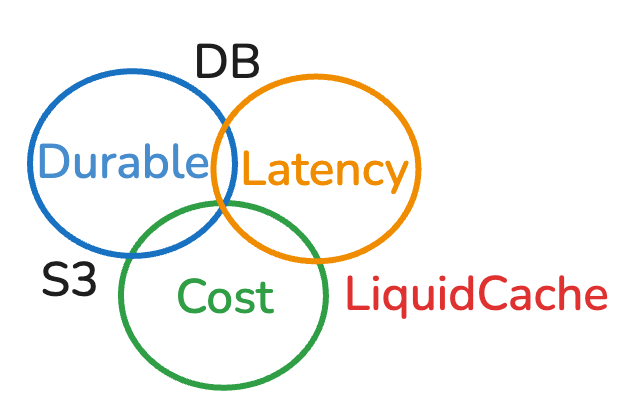
We like S3
- Simple durability: 11 nines of durability—you never have to worry about data loss.
- Simple scalability: virtually unlimited space and throughput.
But S3 is slow and expensive
- ≈100 ms first‑byte latency plus transfer latency; this quickly adds up when multiple round‑trips are needed to fetch data.4
- Storage, request, and data‑transfer/egress costs; prices have remained largely unchanged for a decade even as underlying hardware has become ~20× cheaper.

LiquidCache: foundation of diskless architectures
How LiquidCache Works
We like Parquet
- All major query engines support it (DataFusion, Spark, Trino, DuckDB, Snowflake, BigQuery, and more).
- It is battle‑tested and keeps evolving (e.g., page indexes, new encodings).
- It is under open, stable governance (Apache Software Foundation), so your data is in good hands.
But sometimes we want more aggressive performance
- There are better encodings and compression schemes out there.
- Parquet is critical data infrastructure: it evolves cautiously to keep your data safe and stable—it can’t try new research today and abandon your data tomorrow.
LiquidCache: cache-only, pushdown-optimized data representation
- LiquidCache uses state‑of‑the‑art encodings and compression chosen by the workload.9
- Liquid data is invisible to the rest of the ecosystem: it is cache‑only. This means it can freely change its layout, adding or removing encodings without breaking any user code.
- LiquidCache transparently, progressively, and selectively transcodes Parquet data to the liquid format.
- Liquid data is designed for efficient pushdown to save both compute and network resources.
9 The liquid format is heavily inspired by Vortex. We plan to support a Vortex backend in the future.
Without any changes to Parquet, LiquidCache takes care of the performance optimizations.

Conclusions
LiquidCache is the one‑stop shop for diskless, serverless, and pushdown‑native analytics.
It is built on open standards (Parquet, Arrow Flight, DataFusion) for easy integration and stable governance.
LiquidCache caches Parquet as liquid data, which is ultra-optimized for compute pushdown, compressed execution, modern storage, and network‑efficient data transfer.
Who are we?
- LiquidCache started as a research project led by Xiangpeng Hao at UW‑Madison ADSL.
- It was made possible by a research gift from InfluxData. One year later, SpiralDB and Bauplan also joined the journey.10
- LiquidCache will remain a public‑benefit project in appreciation of the support from taxpayers, research gifts, and the open‑source community.
10 Support our research here!